Introducción
Buenos días tardes o noches compañero, compañera, therian (espero que no) o cualquiera que sea tu espécie, bienvenido a mi blog, resérvate un café para el post de hoy. Vamos a hablar sobre una bestia, un animal de la libreria… Un panda pero no un oso rabioso, sino una biblioteca de python que nos va a ayudar en nuestro dia a dia en el análisis de datos. Espero que te guste el post, allá que vamos con alegría.
Lectura de csv
En este caso vamos a leer un csv.
Pasos:
- Importar la libreria
- Establecer la ruta del archivo
- Darle caña al pc y almacenar los valores en una variable.
Aquí tienes un ejemplo del código: (estoy usando Python)
import pandas as pd
file_path = "./job_salary_prediction_dataset.csv"
job_salary_data = pd.read_csv(file_path)
print(job_salary_data.describe())Con la ejecución de ese comando, podemos ver una pequeña descripción del csv
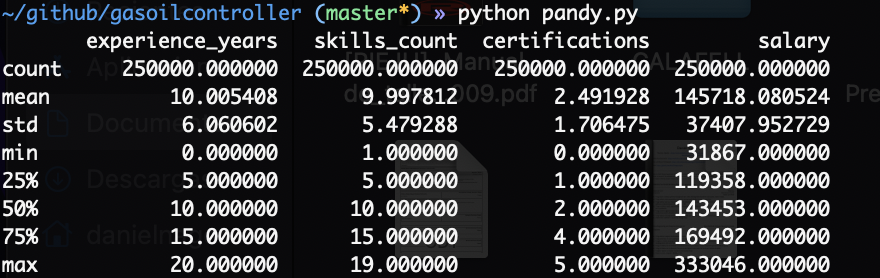
El primer numero, count son los registros que tenemos en el csv. En este caso son 250000. mean es la media de todos los registros por columna. std es la desviación estandard, min son los valores mínimos, el 25% los siguientes… Hasta el max.
Para eliminar los valores nulos del csv, podemos hacer esto:
job_salary_data = job_salary_data.dropna(axis=0)
No es mucho, pero espero que te haya gustado, hasta aquí el post de hoy.